Für Dateien, die von einer externen Quelle importiert werden, können Sie eine automatisch hinzugefügte Eigenschaft festlegen, welche die OCR-Datenquelle verwendet. Die OCR-Datenquelle ist ein auf der Seite festgelegter Bereich. Über OCR erhalten Sie von dem Bereich einen Wert für die ausgewählte Eigenschaft zurück. Im Dialogfeld Eigenschaftsdefinitionen können Sie die Option OCR-Datenquelle verwenden auswählen. Weitere Informationen zum Definieren von verschiedenen Eigenschaften finden Sie unter Metadaten.
Die OCR-Datenquelle kann nur bei externen Quellen verwendet werden. Die OCR-Datenquelle kann nicht in M-Files Desktop definiert werden.
M-Files verwendet ein OCR-Modul von I.R.I.S. Das M-Files-OCR-Modul verfügt auch über Barcodeerkennung. Bei Fragen zum Erwerb des M-Files-OCR-Moduls wenden Sie sich bitte an unser Verkaufsteam unter [email protected].
OCR-Datenquellen definieren
Beginnen Sie mit dem Definieren einer OCR-Datenquelle, indem Sie über die Registerkarte Metadaten des Dialogfelds Neue Verbindung mit externer Quelle eine neue Eigenschaft hinzufügen und anschließend Eine OCR-Datenquelle verwenden und Definieren... auswählen.
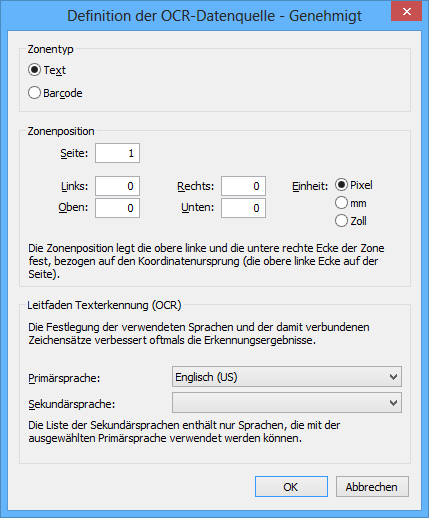
Das Dialogfeld "Definition der OCR-Datenquelle"
Zonentyp
Legen Sie fest, ob die Erkennung über Barcode oder Text erfolgen soll.
Zonenposition
Legen Sie den Bereich fest, in dem bestimmte Zeichen als Werte einer definierten Eigenschaft erkannt werden. Bei diesen Zeichen kann es sich um Buchstaben, Ziffern oder Satzzeichen handeln. So kann z. B. eine auf einer Seite abgebildete Rechnungsnummer dem eingescannten Dokument als Eigenschaftswert Rechnungsnummer hinzugefügt werden. Sie können somit das Scannen und Speichern von festgelegten Dokumenten in M-Files mit stets korrekten Metadaten automatisieren.
Damit der festgelegte Bereich auch korrekt positioniert wird, sollte das zu scannende Dokument wenn möglich per Hand anstatt per Blatteinzug auf der Glasplatte des Scanners platziert werden.
In einigen Fällen gibt OCR möglicherweise ein fehlerhaftes Erkennungsergebnis des Texts aus: so kann beispielsweise, je nach Schriftart oder -größe, die Zahl 1 mit dem Buchstaben I verwechselt werden. Um sicher zu stellen, dass die Zeichen den Dokumenten-Metadaten korrekt hinzugefügt werden, können Sie die Eigenschaftenwerte mit Ereignishandlern und VBScript überprüfen. Mit VBScript können Sie z. B. prüfen, ob alle hinzugefügten Zeichen Zahlen sind. Weitere Informationen finden Sie im Abschnitt Ereignishandler.

Beispiel einer Bereichsdefinition.
Barcode-Erkennung
M-Files erkennt die meisten in Gebrauch befindlichen 1D-Barcodes sowie zwei Arten von 2D-Barcodes: PDF417 und QR-Code.
Muss auf der Seite nur ein Barcode erkannt werden, können Sie die ganze Seite als Zone definieren. Bei mehreren Barcodes müssen Sie die Zone so begrenzen, dass sie nur den gewünschten Barcode enthält. Mit den QR-Codes können Sie einen größeren Bereich als den aktuellen Barcode festlegen.
Befinden sich im festgelegten Bereich mehrere Barcodes, werden alle als Eigenschaftswert betrachtet.
Wenn Sie einen Lizenzcode verwenden, der OCR unterstützt und vor Version 9.0 bereitgestellt wurde, bitten Sie unseren Kundendienst, Ihnen einen neuen Lizenzcode zur Verfügung zu stellen, wenn Sie die Barcodeerkennung verwenden möchten.
Leitfaden Texterkennung (OCR)
Obwohl OCR alle Zeichensätze für westliche Sprachen und Kyrillisch erkennt, verbessert die Angabe einer Sprachauswahl oft die Qualität der Texterkennungsergebnisse.
In nicht eindeutigen Fällen kann ein problematisches Erkennungsergebnis durch einen sprachspezifischen Faktor gelöst werden, so z. B. das Erkennen des finnischen Buchstabens „Ä“. Die Liste der sekundären Sprachen enthält nur Sprachen, die zusammen mit der gewählten Primärsprache verwendet werden dürfen.
Mit der Zonenposition werden die zwei Ecken (oben links und unten rechts) der Zone im Verhältnis zum Ursprung des Koordinatensystems festgelegt, das sich in der oberen linken Ecke der Seite befindet. Im oben genannten Beispiel werden folgende Werte verwendet: links 144 mm, oben 59 mm, rechts 170 mm und unten 68 mm.