Pour effectuer une reconnaissance de texte automatique dans M-Files des fichiers importés à partir du scanner, sélectionnez l'option Utiliser OCR pour activer la recherche plein texte des documents numérisés dans l'onglet PDF avec fonction de recherche de la boîte de dialogue Propriétés de connexion pour une connexion à une source externe. M-Files convertit ensuite les fichiers images importés en PDF avec fonction de recherche afin de permettre une recherche plein texte du document numérisé. Après conversion vous pouvez retrouver le document PDF en recherchant le contenu du document actuel.
La reconnaissance de texte peut être exécutée sur les formats de fichier suivants : TIFF, JPEG, BMP, PNG, et PDF. Les fichiers TIFF utilisant un canal alpha ou une compression JPEG ne sont pas supportés.
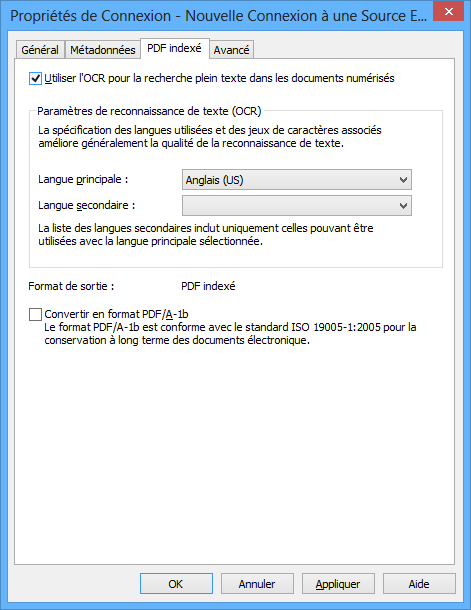
L'onglet "PDF avec fonction de recherche" de la boîte de dialogue "Propriétés de connexion".
Bien que l'OCR reconnaisse automatiquement toutes les langues occidentales, le choix d'une langue améliore souvent la qualité des résultats de la reconnaissance de texte. La liste des langues secondaires ne contient que les langues qui peuvent être utilisées avec la langue principale sélectionnée.
La reconnaissance de texte peut aussi être effectuée dans M-Files Desktop. Pour davantage d'informations, veuillez-vous reporter à la section Numérisation et reconnaissance de texte (OCR). Si vous souhaitez utiliser la reconnaissance de texte avec des sources externes via l'Administrateur M-Files Server uniquement, cette limitation peut être configurée en modifiant les paramètres du registre. Les paramètres de registre peuvent aussi être utilisés pour définir d'autres limitations. Pour de plus amples informations sur les paramètres de registre, contactez l'assistance technique à l'adresse : [email protected].
M-Files utilise un moteur OCR fourni par I.R.I.S. Pour toute question concernant l'achat du module OCR M-Files, veuillez contacter notre équipe des ventes à l'adresse suivante : [email protected].
Convertir au format PDF/A-1b
Sélectionnez cette option si vous voulez respecter la norme ISO 19005-1:2005 pour la conservation à long terme des documents électroniques.
PDF/A-1b est un format plus restreint par rapport au format PDF standard ; ainsi, les fichiers convertis au format PDF/A sont souvent plus volumineux que ceux convertis au format PDF standard. De plus, pendant l'exportation au format PDF/A, certains paramètres avancés d'aspect peuvent être omis. Vous devriez utiliser la conversion au format PDF/A seulement lorsque c'est vraiment nécessaire, pour des conditions de conservation à long terme, par exemple.