Searchable PDF
Note: This content is no longer updated.
For the latest content, please go to the user guide for M-Files Online. For information on the supported product
versions, refer to our lifecycle policy.
M-Files can convert images imported from external file sources into searchable PDFs using optical character recognition (OCR). This makes full-text search of scanned documents possible. After conversion, you can find the PDF document by searching the actual document content.
Optical character recognition can be performed on the
following file formats:
- TIF
- TIFF
- JPG
- JPEG
- BMP
- PNG
Note: Converting the file to a searchable PDF does not affect the outward appearance of
the document when viewing it. The users still see the original scanned image. M-Files stores the automatic text recognition results in the
PDF as invisible text, which is used when searching the file. Possible text
recognition inaccuracies will not affect the appearance of the scanned document in
any way when viewed on screen or printed.
Note: The M-Files OCR module is an M-Files add-on product available for extra fee. It can be activated
with a license code. For more information, see Enabling the M-Files
OCR Module and Managing Server Licenses. M-Files uses an OCR engine offered by IRIS. For
the M-Files OCR module purchase inquiries, please contact our sales
team at [email protected].
Do the following steps to convert images from an external file source into searchable PDFs:
-
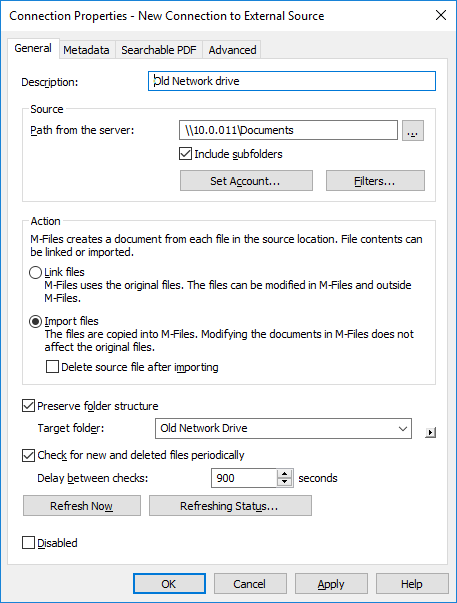
On the File Sources list, double-click the file source
that you want to edit.
Result:The Connection Properties dialog is opened.
-
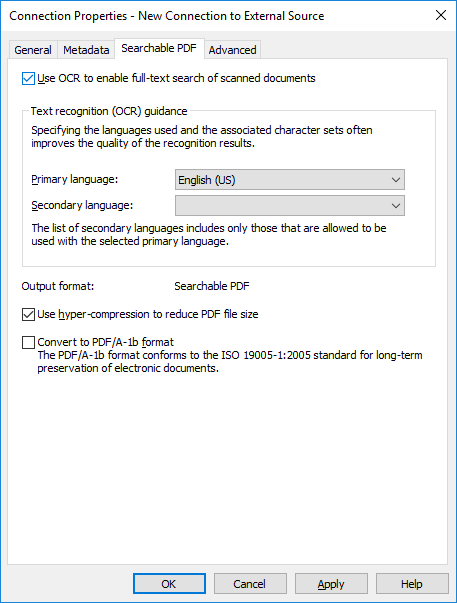
Click the Searchable PDF tab.
Result:The Searchable PDF tab is opened.
Note: Text recognition can also be performed via M-Files Desktop. For more information, refer to Scanning and Text Recognition (OCR). If you wish to use text recognition
using external sources through the M-Files Admin only, this
limitation can be set by changing the registry settings. The registry settings can
be used to set other limitations as well. For more information on registry settings,
write to our customer support at [email protected].