Hakukelpoinen PDF
Huomaa: Tätä sisältöä ei päivitetä. Uusimmat tiedot löydät M-Files Online -käyttöoppaasta. Tietoa tuetuista tuoteversioista löydät elinkaarikäytännöstämme.
M-Files voi muuntaa ulkoisista tiedostolähteistä tuodut kuvat hakukelpoisiksi PDF-tiedostoiksi optisella tekstintunnistuksella (OCR). Se mahdollistaa sisältöhaun skannatuista tiedostoista. Muunnoksen jälkeen voit etsiä PDF-dokumenttia tekemällä haun dokumentin varsinaiseen sisältöön.
Seuraaville tiedostomuodoille voidaan tehdä optinen tekstintunnistus:
- TIF
- TIFF
- JPG
- JPEG
- BMP
- PNG
Huomaa: Hakukelpoiseksi PDF:ksi muuntaminen ei vaikuta siihen, miltä skannattu asiakirja näyttää sitä katseltaessa. Käyttäjät näkevät edelleen alkuperäisen skannatun kuvan. M-Files tallentaa automaattisen tekstintunnistuksen tulokset PDF-tiedostoon näkymättömänä tekstinä, jonka avulla tiedosto voidaan löytää hauilla. Mahdolliset epätarkkuudet tekstintunnistuksen tuloksissa eivät siis vaikuta mitenkään siihen, miltä näin käsitelty skannattu asiakirja näyttää, kun sitä katsellaan kuvaruudulla tai kun se tulostetaan.
Huomaa: M-Files OCR -moduuli on M-Filesin maksullinen lisäosa. Se voidaan ottaa käyttöön lisenssikoodin avulla. Jos tarvitset lisätietoja, katso kohdat Enabling the M-Files
OCR Module ja Palvelinlisenssien hallinta. M-Files käyttää OCR-moottoria, jonka tarjoaa IRIS. Jos haluat ostaa M-Files OCR -moduulin, ota yhteyttä myyntiimme osoitteessa [email protected].
Muunna ulkoisen tiedostolähteen kuvat hakukelpoisiksi PDF-tiedostoiksi seuraavasti:
-
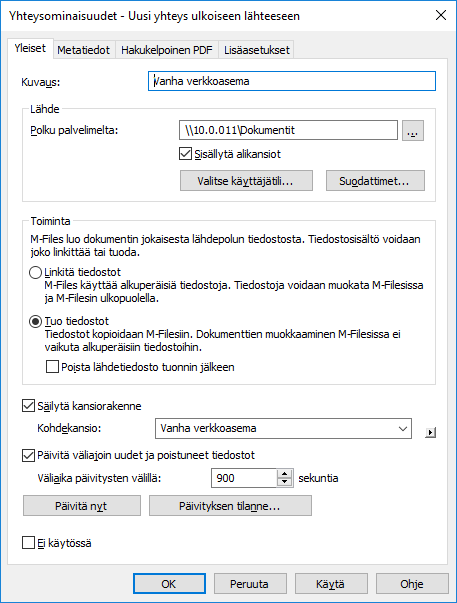
Kaksoisnapsauta Tiedostot-luettelosta tiedostoa, jota haluat muokata.
Tulos:Yhteysominaisuudet-ikkuna avautuu.
-
Napsauta Hakukelpoinen PDF -välilehteä.
Tulos:Hakukelpoinen PDF -välilehti avautuu.

Huomaa: Myös M-Files Desktopin puolella voidaan tehdä tekstintunnistus. Katso lisätietoja luvusta Skannaus ja tekstintunnistus (OCR). Mikäli tekstintunnistusta halutaan käyttää ainoastaan M-Files Adminin kautta ulkoisia lähteitä käyttämällä, tämä rajaus voidaan tehdä rekisteriasetuksia muuttamalla. Rekisteriasetuksilla voidaan tehdä myös muita rajauksia. Jos haluat lisätietoja rekisteriasetuksista, ota yhteyttä asiakastukeemme osoitteessa [email protected].