Searchable PDF
M-Files can convert images imported from external file sources into searchable PDFs using optical character recognition (OCR). This makes full-text search of scanned documents possible. After conversion, you can find the PDF document by searching the actual document content.
You can use optical character recognition with these file formats:
- TIF
- TIFF
- JPG
- JPEG
- BMP
- PNG
Note: Converting the file to a searchable PDF does not affect the outward appearance of the document
when viewing it. The users still see the original scanned image. M-Files
stores the automatic text recognition results in the PDF as invisible text, which is used when
searching the file. Possible text recognition inaccuracies will not affect the appearance of the
scanned document in any way when viewed on screen or printed.
Note: When you use the OCR feature in M-Files on a
signed PDF, the entire document is rewritten. Because digital signatures validate the
content, any edits made by OCR will invalidate the existing signature. This can result in
the signature's removal.
Do the following steps to convert images from an external file source into searchable PDFs:
-
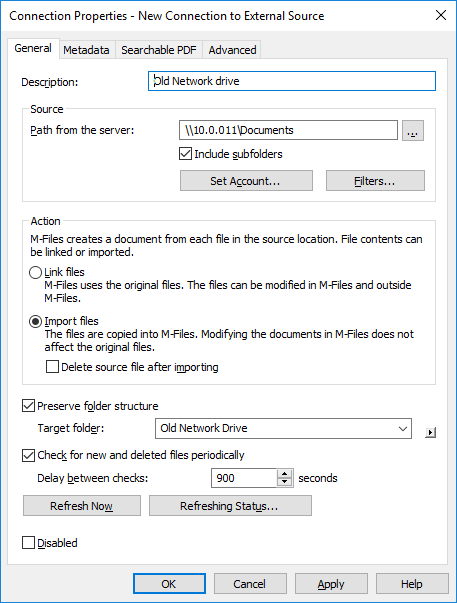
On the File Sources list, double-click the file source that you want to
edit.
Result:The Connection Properties dialog is opened.
-
Click the Searchable PDF tab.
Result:The Searchable PDF tab is opened.
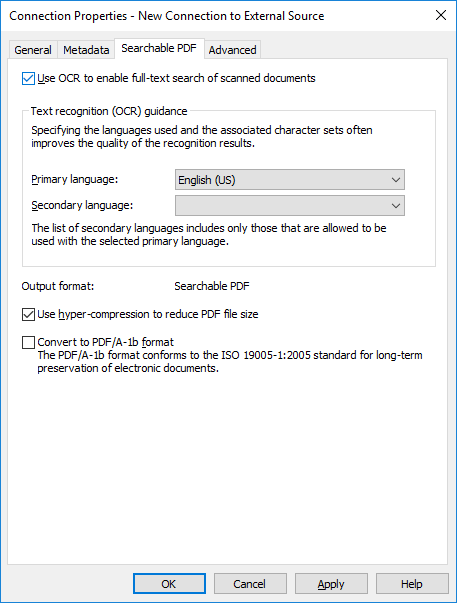
Note: Text recognition
can also be done in the classic M-Files Desktop. For more information, see Scanning and text recognition (OCR). To use text recognition using external sources through
the M-Files Admin only, this limitation can be set by changing the registry settings.
The registry settings can be used to set other limitations as well. For more information on registry
settings, contact our customer support in M-Files Support Portal or your M-Files
reseller.