Defining an OCR Value Source
You can extract text or barcodes from a scanned document using optical character recognition (OCR) and use them as automatic property values for files imported from an external source, a scanner in this case. The OCR value source is a zone defined on a scanned page. For more information on defining different properties for objects imported from external file sources, see Defining metadata for an external file source.
- TIF
- TIFF
- JPG
- JPEG
- BMP
- PNG
The use of an OCR value source is only possible when using an external source.
Do the following steps to define an OCR value source:
-
On the File Sources list, double-click the file source that you want to
edit.
Result:The Connection Properties dialog is opened.
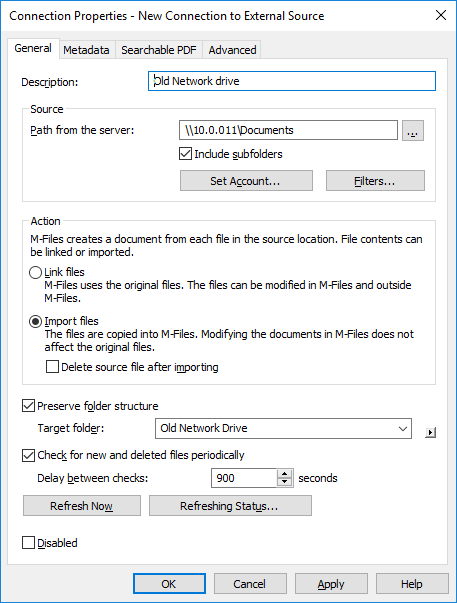
-
Click the Metadata tab.
Result:The Metadata tab is opened.
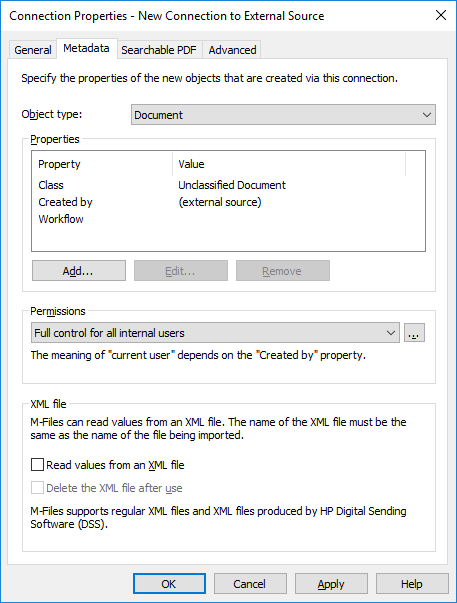
-
Click Add... to define a new property and value to be added automatically
for objects created from external files, or select one of the existing properties and click
Edit... to edit the existing property.
Result:The Define Property dialog is opened.
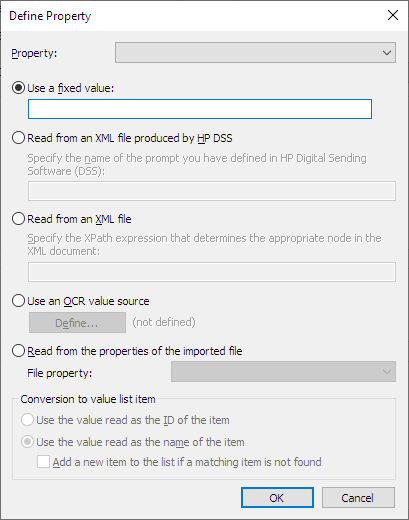
-
Select the option Use an OCR value source and click the
Define... button.
Result:The OCR Value Source Definition dialog is opened.
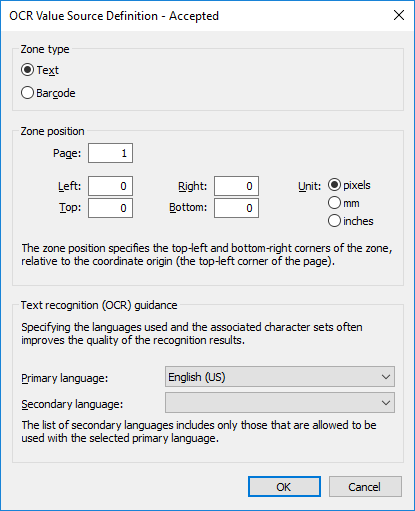
-
In the Zone position section, define a zone from which to extract a value
for the selected property. The characters may include any letters, numbers or punctuation marks. For
example, an invoice number shown on a page can be added as the Invoice number property value
for the scanned document.
Example:An example of a zone definition:
 If you are capturing a barcode and there is only one barcode to recognize on the page, you can specify the whole page as the zone. If there are several barcodes, restrict the zone in a such a way that it contains the desired barcode only. With QR codes, you should specify a zone larger than the actual barcode. If the specified zone has several barcodes, all of them are considered to be a property value.
If you are capturing a barcode and there is only one barcode to recognize on the page, you can specify the whole page as the zone. If there are several barcodes, restrict the zone in a such a way that it contains the desired barcode only. With QR codes, you should specify a zone larger than the actual barcode. If the specified zone has several barcodes, all of them are considered to be a property value.- In the Page field, enter the page number of the scanned document that you want to use as the OCR value source.
- Using the Unit options, select the appropriate unit for defining the zone position.
- In the Left field, enter the left corner position of the OCR zone. The left corner of the scanned document is considered "0".
- In the Right field, enter the right corner position of the OCR zone.
- In the Top field, enter the top corner position of the OCR zone. The top corner of the scanned document is considered "0".
- In the Bottom field, enter the bottom corner position of the OCR zone.
To make sure that the specified zone is correctly positioned, in most cases the document to be scanned must be placed onto the scanner glass by hand.
In some cases, the OCR can give an incorrect recognition result of the text. For example, depending on the font type or size, the number 1 can be interpreted as the letter I. To make sure that the characters are added correctly to metadata, you can check the property values with event handlers and VBScript. You can then use VBScript to check, for example, that all added characters are numbers. For more information, see Event handlers.
Supported barcode types
The M-Files OCR module supports the following barcode types:
- QR Code
- Data Matrix
- Aztec Code
- EAN-13
- EAN-8
- EAN-5
- EAN-2
- MSI Plessley
- MSI Pharma
- UPC-A
- UPC-E
- Codabar
- Interleaved 2 of 5
- Discrete 2 of 5
- Code 39
- Code 39 Extended
- Code 39 HIBC
- Code 93
- Code 128
- PDF 417
- Postnet
- Postnet 32
- Postnet 52
- Postnet 62
- Patchcode
- UCC-128
- UPCE Extended
- IATA 2 of 5
- Datalogic 2 of 5
- Reverse 2 of 5
- Code 39 (out-of-spec)
- Code 128 (out-of-spec)
- Codabar (out-of-spec)