OCR-Datenquelle definieren
Sie können Text oder Barcodes aus einem gescannten Dokument extrahieren, indem Sie die optische Zeichenerkennung (OCR) anwenden und als automatische Eigenschaftswerte für aus einer externen Quelle (Scanner) importierte Dateien verwenden. Die OCR-Datenquelle ist ein auf der gescannten Seite festgelegter Bereich. Für weitere Information über das Festlegen von unterschiedlichen Eigenschaften für importierte Objekte von externen Datenquellen, siehe Metadaten für eine externe Dateiquelle definieren.
- TIF
- TIFF
- JPG
- JPEG
- BMP
- PNG
Die OCR-Datenquelle kann nur bei externen Quellen verwendet werden.
Die folgenden Schritte befolgen, um eine OCR-Datenquelle zu definieren:
-
In der Dateiquellen Liste auf die Dateiquelle doppelklicken, die Sie bearbeiten wollen.
Ergebnis:Das Verbindungseigenschaften Dialogfeld wird geöffnet.

-
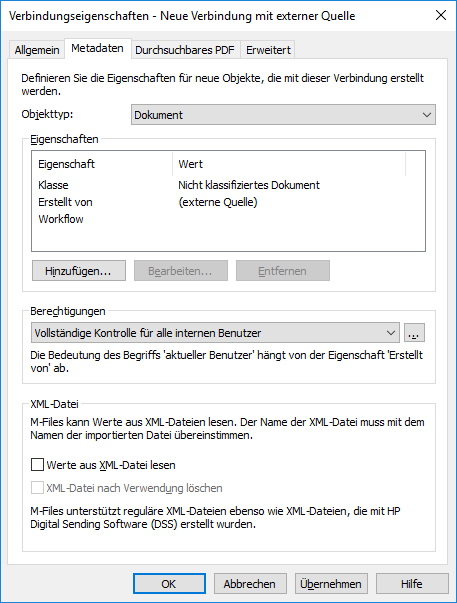
Auf die Metadaten Registerkarte klicken.
Ergebnis:Die Metadaten Registerkarte wird geöffnet.
-
Auf Hinzufügen... klicken, um die neuen Eigenschaften und Werte zu definieren, die automatisch jedem Objekt hinzugefügt werden, die von externen Dateien erstellt wurden oder eine der bestehenden Eigenschaften auswählen und auf Bearbeiten... klicken, um die bestehende Eigenschaft zu bearbeiten.
Ergebnis:Das Eigenschaftsdefinition Dialogfeld wird geöffnet.

-
Die Option OCR-Datenquelle verwenden auswählen und anschließend auf die Definieren... Schaltfläche klicken.
Ergebnis:Das Definition der OCR-Datenquelle Dialogfeld wird geöffnet.
-
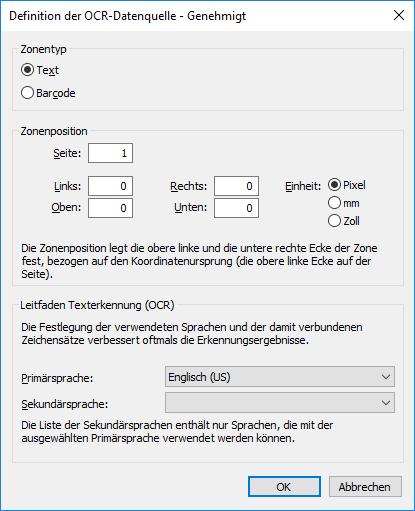
Im Zonenposition Abschnitt eine Zone definieren, von der die Werte für die ausgewählte Eigenschaft extrahiert werden. Bei diesen Zeichen kann es sich um Buchstaben, Ziffern oder Satzzeichen handeln. So kann z. B. eine auf einer Seite abgebildete Rechnungsnummer dem eingescannten Dokument als Eigenschaftswert Rechnungsnummer hinzugefügt werden.
Beispiel:Beispiel einer Bereichsdefinition:
 Falls Sie einen Barcode lesen und nur ein einziger Barcode auf der Seite zur Erkennung vorhanden ist, können Sie die gesamte Seite als Bereich definieren. Bei mehreren Barcodes müssen Sie die Zone so begrenzen, dass sie nur den gewünschten Barcode enthält. Mit den QR-Codes können Sie einen größeren Bereich als den aktuellen Barcode festlegen. Befinden sich im festgelegten Bereich mehrere Barcodes, werden alle als Eigenschaftswert betrachtet.
Falls Sie einen Barcode lesen und nur ein einziger Barcode auf der Seite zur Erkennung vorhanden ist, können Sie die gesamte Seite als Bereich definieren. Bei mehreren Barcodes müssen Sie die Zone so begrenzen, dass sie nur den gewünschten Barcode enthält. Mit den QR-Codes können Sie einen größeren Bereich als den aktuellen Barcode festlegen. Befinden sich im festgelegten Bereich mehrere Barcodes, werden alle als Eigenschaftswert betrachtet.- Im Seite Feld die Seitenanzahl der gescannten Dokumente eingeben, die Sie als OCR-Datenquelle festlegen wollen.
- Mithilfe der Optionen Einheit, die geeignete Einheit zur Definition des Bereichs festlegen.
- Im Links Feld die linke Eckposition des OCR-Bereichs eingeben. Die linke Ecke des gescannten Dokuments wird als „0“ betrachtet.
- Im Rechts Feld die rechte Eckposition des OCR-Bereichs festlegen.
- Im Oben Feld die obere Eckposition des OCR-Bereichs festlegen. Die obere Ecke des gescannten Dokuments wird als „0“ betrachtet.
- Im Unten Feld die untere Ecke des OCR-Bereichs festlegen.
Um sicherzustellen, dass der angegebene Bereich auch korrekt positioniert wird, muss das zu scannende Dokument wenn möglich manuell auf der Glasplatte des Scanners platziert werden.
In bestimmten Fällen kann OCR falsche Resultate bei der Texterkennung liefern. Abhängig von der Schriftart und -größe kann 1 dann möglicherweise fälschlicherweise als Buchstabe I erkannt werden. Um sicher zu stellen, dass die Zeichen den Metadaten korrekt hinzugefügt werden, können Sie die Eigenschaftenwerte mit Ereignishandlern und VBScript überprüfen. Mit VBScript können Sie z. B. prüfen, ob alle hinzugefügten Zeichen Zahlen sind. Weitere Informationen finden Sie im Abschnitt Ereignishandler.
Unterstützte Barcodetypen
Das M-Files OCR-Modul unterstützt folgende Barcodetypen:
- QR-Code
- Data Matrix
- Aztec Code
- EAN-13
- EAN-8
- EAN-5
- EAN-2
- MSI Plessley
- MSI Pharma
- UPC-A
- UPC-E
- Codabar
- Interleaved 2 of 5
- Discrete 2 of 5
- Code 39
- Code 39 Extended
- Code 39 HIBC
- Code 93
- Code 128
- PDF 417
- Postnet
- Postnet 32
- Postnet 52
- Postnet 62
- Patchcode
- UCC-128
- UPCE Extended
- IATA 2 of 5
- Datalogic 2 of 5
- Reverse 2 of 5
- Code 39 (out-of-spec)
- Code 128 (out-of-spec)
- Codabar (out-of-spec)